|
|
BuzzTrans
Building and evaluating a translating Instant Messenger client
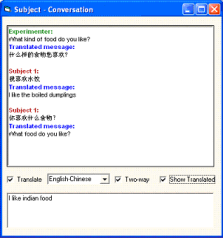 BuzzTrans is a
translating Instant Messenger program that I wrote as part
of a group project for the
Global Classroom Project (LCC6320). This was the graduate version
of LCC4406 which was a class co taught with the European University in
St. Petersburg which required constant interaction between a group of
undergraduates at Georgia Tech and a similar group of undergraduates
at the European University in St. Petersburg, Russia. BuzzTrans is a
translating Instant Messenger program that I wrote as part
of a group project for the
Global Classroom Project (LCC6320). This was the graduate version
of LCC4406 which was a class co taught with the European University in
St. Petersburg which required constant interaction between a group of
undergraduates at Georgia Tech and a similar group of undergraduates
at the European University in St. Petersburg, Russia.
I modified the open source
TechJab Jabber client to use a free translation web based translation
service provided by Systran.
Users were able to select translation between 9 different languages
including English, Russian, Chinese, Japanese, Korean, French and German.
They could also select if they wanted a two way translation and if they
wanted to see the translated text.
The next step was to evaluate the viability of BuzzTrans as an informal real time communication tool. In order to do this
we faced several challenges including dependance on translation quality,
generalizability of results and creating a standardized and reproducable
yet informal conversation.
In order to achieve these goal we decided to use the cultural diversity
of Georgia Tech to our advantage and test the performance of the IM client
with multiple languages. this not only increased our subject pool but also
achieved language independance creating a generalizable result. To create a
a standardized conversation we would have the subject converse with one of
our group members. We also created a list of 26 questions that we would ask
the subjects during the course of the conversation. These questions were
carefully chosen include context specific information, pop culture
references, acronyms and statements that were difficult to translate. We also
asked the subjects to give us their subjective opinions of the messages they
received. The subject were given no help or coaching and were told to ask the
experimenter to repeat himself if they didnt understand the messages.
Results
Some of the results we obtained are:
- Users were comfortable with the translation as long as they were explicitly told that it was done by a machine
- Shared context allows users to understand many missed translations (Eg. Pop culture, school specific references)
- If the user has a good understanding of the other language they can quickly understand translation errors
- Users adapt to consistant translation errors by modifying their speech
- The need to add an Escape sequence so that users could indicate sections of a comment that were not to be translated
- The need of a transliteration sequence to handle names in languages with different scripts (E.g. Chines, Japanese, etc...)
To learn more about the project and our results please read our paper from ICHI 2004.
- Justin Godfrey
- Rahul Nair
- Kedar Shiroor
|